Computação Paralela
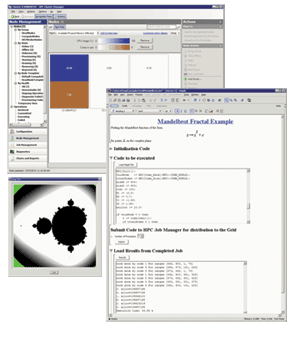
O "Maple Grid Computing Toolbox", caixa de ferramentas para computação paralela em rede de super computadores e ou com processadores com vários núcleos, o que permite que você execute cálculos do Maple, em paralelo, aproveitando-se de todos os seus recursos de hardware, reduzindo o tempo de processamento, e permitindo que os aplicativos que não eram possíveis antes sejam executados.
O "Maple Grid Computing Toolbox" permite a você implantar os seus programas para clusters de computação paralela de grande porte e supercomputadores, tirando proveito de todo o poder de processamento disponível para enfrentar grandes problemas. Isso permite a você lidar com problemas que não são tratáveis em uma única máquina por causa de limitações de memória ou porque ele simplesmente leva muito tempo. O "Grid Computing Toolbox" (Caixa de Ferramentas para Computação Paralela) é muito fácil de configurar. Ele pode se conectar diretamente em seu "cluster HPC Server" existente no Windows ® sem a necessidade de configurar os serviços em cada nó. Você também pode iniciar um processo em cada computador no servidor, em uma rede e a rede se auto-montar em cada nó e é detecta automaticamente os outros nós que estão presentes. O "Grid Computing Toolbox" também se integra aos sistemas de agendamento de tarefas existentes, como PBS. O Maple inclui a capacidade de configurar facilmente cálculos multi-processamento em um único computador. O "Maple Grid Computing Toolbox" estende esse poder de multi-máquinas ou paralelismo cluster. As duas versões são totalmente compatíveis, de modo que um algoritmo pode ser criado e totalmente testados usando a implementação local dentro do Maple, e em seguida implantados no conjunto completo usando a caixa de ferramentas, sem alterações no algoritmo. Para realizar cálculos distribuídos, a a caixa de ferramentas de computação em paralelo, oferece uma variedade de ferramentas:
 |
 |
- Mensagem MPI padrão passando no Windows HPC Server, para uma comunicação eficiente e integração com ferramentas que suportam este protocolo.
- Mensagem MPI passando no Linux utilizando o protocolo MPICH2, uma implementação de alto desempenho do padrão MPI distribuído pela Argonne National Laboratory.
- Uma passagem de mensagens API MPI-like, que está disponível em todas as plataformas. Este API é parte do "Grid Computing Toolbox", então, quando usando este protocolo, não há drivers especiais ou outras ferramentas não precisam ser instalados nos computadores. Além de simplificar a configuração da rede, este protocolo também é ideal para computação paralela em um único computador e os cálculos através de redes heterogêneas.
- Um conjunto de comandos de alto nível em Maple para a definição de computações paralelas.
- Distribuir os cálculos do Maple através de uma rede
- Integração com o Microsoft Windows HPC Server, incluindo o Windows HPC Server 2008 R2
- Grade de auto-montagem em redes locais
- Simples de usar, interface interativa para o lançamento de trabalhos paralelos
- Ferramentas para desenvolver e testar aplicativos na área de trabalho antes da implantação
- Integração com PBS e outros sistemas de agendamento de tarefas
- Mensagem MPI e MPI-like API passando (enviar, receber, etc)
- Detecção e recuperação automática de impasse
- Comandos de paralelização de alto nível (mapa, seq, etc)
- Algoritmo paralelo de dividir e distribuir genérico,
- Muitos exemplos documentados
- Suporte para redes heterogêneas
- O acesso a todo o poder computacional do Maple
O "Grid Computing Toolbox" está disponível em duas versões diferentes:
- A Edição Pessoal suporta até 8 CPUs no cluster.
- O Cluster Edition suporta um número ilimitado de CPUs no cluster.
Ambas as versões estão disponíveis .
Note-se que uma licença do Maple é necessária para cada nó no cluster. Preço por volume está disponível para as instalações do nó do Maple. Para obter detalhes Contate-nos.
O Maple 15 estabelece um recorde mundial para o cálculo de uma constante que você provavelmente nunca ouviu falar...
O problema
Em 1996, eu estava trabalhando para o Grupo de Computação Simbólica na Universidade de Waterloo, o desenvolvimento de algoritmos e código para a avaliação da precisão arbitrária de funções especiais. Eu recebi um email de Peter Borwein na Simon Fraser University relatando um possível bug no código do Maple para a função zeta de Riemann, que eu tinha escrito para o lançamento atual então. O Peter estava correto e eu reparei o erro, mas eu estava curioso sobre como ele havia descoberto em primeiro lugar, uma vez que não apareceu até vários milhares de dígitos de alguns valores da função zeta serem calculados.
Peter estava tentando calcular um valor de alta precisão para a constante de Landau-Ramanujan, que é definido como:
![]()
, Onde ![]() é o número de inteiros positivos menores ou iguais ao
é o número de inteiros positivos menores ou iguais ao ![]() que pode ser escrito como a soma de exatamente dois quadrados. A convergência desta fórmula é extremamente lenta, gerando um dígito
que pode ser escrito como a soma de exatamente dois quadrados. A convergência desta fórmula é extremamente lenta, gerando um dígito ![]() . Ramanujan calculado K ≈ 0,764. Em 1908, Landau revelou
. Ramanujan calculado K ≈ 0,764. Em 1908, Landau revelou

, Onde ![]() é o conjunto dos números primos. Isso é melhor, mas ainda é muito lento: usando primos <100000 dá 6 dígitos para K.
é o conjunto dos números primos. Isso é melhor, mas ainda é muito lento: usando primos <100000 dá 6 dígitos para K.
Em 1996, Flajolet & Vardi [1] derivadas da fórmula notável

onde ![]() é a função zeta de Riemann e
é a função zeta de Riemann e ![]() é a função beta Dirichlet. Esta fórmula é extremamente convergente rapidamente: 9 termos dar cerca de 500 dígitos, 10 termos quase 1000 dígitos, 11 termos quase 2000 dígitos, e assim por diante. Foi a publicação desta fórmula que levou Peter Borwein tentar o cálculo
é a função beta Dirichlet. Esta fórmula é extremamente convergente rapidamente: 9 termos dar cerca de 500 dígitos, 10 termos quase 1000 dígitos, 11 termos quase 2000 dígitos, e assim por diante. Foi a publicação desta fórmula que levou Peter Borwein tentar o cálculo ![]() no Maple, e levou à sua descoberta do erro do código zeta.
no Maple, e levou à sua descoberta do erro do código zeta.
A função beta Dirichlet tem uma representação em termos de Hurwitz (ou generalizadas) funções zeta:
![]()
onde  . Note-se a relação entre as funções zeta Riemann e Hurwitz:
. Note-se a relação entre as funções zeta Riemann e Hurwitz: ![]() . Para inteiros pares
. Para inteiros pares ![]() , a função zeta de Riemann tem uma forma simples em termos de números de Bernoulli:
, a função zeta de Riemann tem uma forma simples em termos de números de Bernoulli:
![]() pois mesmo n
pois mesmo n
Agora, depois de ter encontrado e corrigido o problema que Pedro relatou, eu decidi ver o quão longe eu poderia empurrar esse cálculo, ou seja, quantos dígitos de ![]() que eu poderia calcular no Maple. Flajolet tinha usado sua nova fórmula para obter 1.024 dígitos.
que eu poderia calcular no Maple. Flajolet tinha usado sua nova fórmula para obter 1.024 dígitos.
O algoritmo
A maior parte do trabalho é os cálculos da função zeta de Hurwitz, que são feitas no Maple usando a fórmula da soma de Euler-MacLaurin:

Esta fórmula requer números de Bernoulli, muitos deles de alta precisão. A fórmula padrão para números de Bernoulli é

Nota ![]() para ímpar
para ímpar ![]() .
. ![]() ,
, ![]() mesmo, é racional (com tipicamente um pequeno denominador), não inteiro. Esta fórmula é altamente recursiva, com cada número de Bernoulli diferente de zero definida em termos de todos os anteriores. É realmente apenas utilizável até cerca
mesmo, é racional (com tipicamente um pequeno denominador), não inteiro. Esta fórmula é altamente recursiva, com cada número de Bernoulli diferente de zero definida em termos de todos os anteriores. É realmente apenas utilizável até cerca ![]() . Usando todos os itens acima, em 1996, eu era capaz de calcular 10.000 dígitos
. Usando todos os itens acima, em 1996, eu era capaz de calcular 10.000 dígitos ![]() . Demorou uma semana inteira de tempo de CPU sobre o que era, para o seu dia, um computador muito poderoso.
. Demorou uma semana inteira de tempo de CPU sobre o que era, para o seu dia, um computador muito poderoso.
O próximo avanço tecnológico que permitiu maior precisão do cálculo ![]() ocorreu em 2007, com a publicação por Fee & Plouffe [2] de um algoritmo rápido, direto para a contagem dos números de Bernoulli. Este algoritmo é derivado a partir da observação inteligente que o número inteiro e partes fraccionada dos números de Bernoulli pode ser computado separadamente, por algoritmos diferentes, cada um dos quais é muito eficiente. Primeiro, virar a fórmula acima para a função zeta de Riemann em valores ainda inteiros:
ocorreu em 2007, com a publicação por Fee & Plouffe [2] de um algoritmo rápido, direto para a contagem dos números de Bernoulli. Este algoritmo é derivado a partir da observação inteligente que o número inteiro e partes fraccionada dos números de Bernoulli pode ser computado separadamente, por algoritmos diferentes, cada um dos quais é muito eficiente. Primeiro, virar a fórmula acima para a função zeta de Riemann em valores ainda inteiros:

Em seguida, usamos a fórmula clássica para ![]() , em termos de números primos:
, em termos de números primos:

Esta representação converge lentamente para o valor exato ![]() , mas apenas muito poucos termos de produto são necessários para obter a parte inteira
, mas apenas muito poucos termos de produto são necessários para obter a parte inteira ![]() .
.
A fórmula diferente muito rapidamente dá a parte fracionária de ![]() :
:

Usando esta abordagem, pode-se calcular um número qualquer de Bernoulli muito rapidamente, e de forma independente de qualquer outro número de Bernoulli, o que significa que o algoritmo é completamente "parallelizable".
Juntando tudo, temos de calcular

Para cada termo do produto que precisa de 2 cálculos zeta de Hurwitz, um número extra de Bernoulli e um fatorial. Os cálculos da função zeta vai precisar de muitos números de Bernoulli, mas para a maior parte dos cálculos diferentes zeta irá usar os mesmos números de Bernoulli, de modo que o primeiro passo é "precompute" e armazená-los. Extrapolando a partir de cálculos de precisão inferiores, eu determinei que eu precisaria de mais do que sobre os primeiros 57 mil não-zero números de Bernoulli para calcular ![]() a cerca de 128.000 dígitos, mais um pouco mais para os fatores da fórmula
a cerca de 128.000 dígitos, mais um pouco mais para os fatores da fórmula ![]() , assim que eu definir um trabalho do Maple executando para coletar todos estes enquanto eu trabalhava no código para o cálculo principal.
, assim que eu definir um trabalho do Maple executando para coletar todos estes enquanto eu trabalhava no código para o cálculo principal.
Com os números de Bernoulli agora essencialmente livres, todo o custo da computação ![]() está nos cálculos zeta de Hurwitz. Note-se que estes cálculos são independentes uns dos outros.
está nos cálculos zeta de Hurwitz. Note-se que estes cálculos são independentes uns dos outros.
A tecnologia
A Maple tem um sistema de 24-nó que executa o sistema operacional da Microsoft HPC Server 2008 R2. Usando o Maple Grid Computing Toolbox, podemos enviar uma tarefa - um arquivo de comandos do Maple - a este sistema e obter (quase) 24X a paralelização, por muito pouco esforço.
Nós se comunicam através do envio de mensagens usando o sistema MPI. Os comandos do Maple Grid Computing Toolbox em Maple necessário para este projeto são:
| MPI:-Init () | - | Instalação |
| MPI:-Comm_Rank (MPI:-COMM_WORLD) | - | Quem sou eu? |
| MPI:-Send (MPI:-COMM_WORLD, dest, msg ) | - | Enviar msg para o nó dest |
| MPI:-Receive (MPI:-COMM_WORLD,src ) | - | Receber uma mensagem de src (que pode ser MPI:-ANY_SOURCE) |
| MPI:-Comm_Size (MPI:-COMM_WORLD) | - | Número de nós disponíveis para a computação |
| MPI:-Finalize () | - | Node é feito |
A manipulação dos números de Bernoulli acabou por ser um pouco complicado, devido à configuração do sistema de hardware. Especificamente, os nodos 24 da plataforma de rede que estão organizados em três "planos" de 8 nós de cada. Os 8 nós em um compartilhamento de plano 8GB de memória RAM. Quando a memória exigida pelos cálculos zeta e a memória já em uso pelo o / s é contabilizada, não há espaço suficiente para armazenar todos os números de Bernoulli 57.000 pré-computados -. Armazenado em formato m Maples, eles exigem mais do que 6GB de memória. Isto significa que um nó não pode servir a todos os números de Bernoulli necessários (bem, poderia se não mantê-los todos na memória, mas uma vez que os diferentes nós será tipicamente em diferentes pontos em seus cálculos zeta é difícil imaginar como isso poderia ser feito de forma eficiente).
Em vez disso, eu experimentei com dois métodos diferentes:
| 1. |
Selecione um nó em cada plano como um servidor de número de Bernoulli, com o nó no plano 1 servindo os primeiros mil números de Bernoulli não-zero, o nó no plano 2 no próximo 1000, o nó no plano 3 do próximo 1000, e de volta ao primeiro para os próximos 1000, e assim por diante, em consequência, apenas 21 nós estão disponíveis para os cálculos zeta. |
| 2. |
Já cada nó lê os números de Bernoulli que precisa (de novo em lotes de 1000, como é assim que eu escolhi para armazená-los no disco), e, em seguida, descartar aqueles (que permite que a memória seja recuperada), quando um novo lote é necessário. Neste projeto, 23 nós estão disponíveis para cálculos zeta (nó 0 gerencia o trabalho em geral). |
Uma otimização foi derivada de observações do tempo de computação para cada valor zeta.Especificamente, os cálculos para termos perto do meio do conjunto necessário geralmente levou mais tempo, de modo que aqueles foram entregues para os nós de computação mais antigos.
O código para o método (2) é ligado. Observa-se que o design é uma bomba de mensagem bastante simples: Nó 0, o nó mestre, continuamente executa um "receber - respondem" loop, escutando e interpretando as mensagens dos outros nós. As diferentes mensagens de cada composto de um código de mensagem (por exemplo, 1 = "Eu preciso de mais trabalho") e qualquer outra informação que o nó mestre necessita para responder. Da mesma forma, os nós dos trabalhos (nós 1-23) trabalho pedido a partir do nó principal, leva a cabo a missão que lhes é dado, envia o resultado de volta e pede mais trabalho. O ponto aqui é que a obtenção de acesso a um sistema de rede pode ser a parte mais difícil. Usando a caixa de ferramentas para implantar postos de tarefas no "grid" é muito simples.
Os resultados
Esta tabela resume os resultados. A primeira coluna indica o ajuste de dígitos para o cálculo. A segunda coluna indica o número de termos da fórmula do produto Flajolet-Vardi usado para o cálculo. A terceira coluna indica o número de dígitos considerado correto. Este valor é obtido através da comparação com o valor obtido para a próxima linha para baixo na tabela. É por isso que o último cálculo, em 128.000 dígitos, inclui um termo extra. A quarta coluna especifica o maior número de Bernoulli índice exigido pelos cálculos zeta de Hurwitz, com todos os números de Bernoulli o índice mais elevado exigido pela fórmula do produto dado entre parênteses. Note-se que o último resultado requer dois números de Bernoulli, que não estão entre os pré-computados 57.000 valores diferentes de zero. Estes também foram pré-computados usando a fórmula direta Fee-Plouffe , exigindo muito pouco tempo (em termos relativos).
Descobriu-se que o método do número de Bernoulli (1) exigiu a menor quantidade de memória total, cerca de 5GB de cada plano. No entanto, o método (2), que é necessário para fechar a RAM máxima disponível em cada plano, era visivelmente mais rápido para os cálculos de precisão elevados. A última coluna do quadro indica o tempo requerido pelo (2) método da versão.
|
Digitos |
# Termos |
Precisão do resultado |
Max. (Não 0) número de Bernoulli |
Tempo |
|
1000 |
10 |
979 |
1200 |
1,0 seg |
|
2000 |
11 |
1957 |
2272 |
1.8 sec |
|
4000 |
12 |
3911 |
4262 |
8,5 seg |
|
8000 |
13 |
7820 |
<8000 (8192) |
46 seg |
|
16000 |
14 |
15637 |
<16000 (16384) |
4,5 min |
|
32000 |
15 |
31272 |
<28000 (32768) |
33 min |
|
64000 |
16 |
62541 |
<54000 (65536) |
3,4 hr |
|
128000 |
18 |
125079 |
<108000 (131072, 262144) |
15,3 hr |
Aqui estão os registros da computação anteriores. A quinta entrada é um valor sem créditos, que foi encontrado na Enciclopédia On-Line de seqüências inteiras , onde o recorde atual de 125.079 dígitos está agora armazenado.
|
Ramanujan |
3 |
w 1910 |
|
Flajolet |
1024 |
1996 |
|
Rabit |
10.000 |
1996 |
|
Sebah |
30.010 |
2002 |
|
65.536 |
? |
|
|
Rabit |
125079 |
2010 |